

Opis przeznaczenia maszyny proxy
1) Jedno IP / jeden punkt wejścia do klastra
Zamiast uczyć użytkowników/usługi, że API jest raz na master1, raz na master2, a czasem master3, dajesz im:
1 adres DNS/IP dla API (np. api.okd.example)
1 adres DNS/IP dla aplikacji (np. apps.okd.example)
HAProxy stoi przed klastrem i “za kulisami” rozkłada ruch na odpowiednie backendy.
To jest ważne, bo:
węzły mogą paść,
węzły mogą być restartowane,
podczas upgrade / zmian routingu nie chcesz zmieniać IP w każdym kliencie.
2) Load balancing do API (control plane) – port 6443
Najbardziej krytyczna funkcja:
Ruch na:
api.<cluster> → TCP/6443
HAProxy rozdziela to na master/control-plane:
master-1:6443
master-2:6443
master-3:6443
Kto korzysta z tego portu?
oc, kubectl (Ty jako admin)
komponenty klastra (kubelet, kontrolery, operatory)
installer / bootstrap w trakcie instalacji
automatyzacje CI/CD, monitoring, itd.
Bez LB: w praktyce tracisz HA dla API – bo jak padnie ten “jeden master, na który wskazuje DNS”, to klaster dla klientów jest “martwy”, mimo że inne mastery żyją.
3) Load balancing do Machine Config Server (MCS) – port 22623
Drugi port, który bardzo często idzie przez HAProxy:
Ruch na:
api.<cluster> lub api-int.<cluster> → TCP/22623
To jest Machine Config Server, używany głównie podczas:
instalacji,
dołączania nowych węzłów,
pobierania konfiguracji/ignition,
wczesnego bootstrapa.
HAProxy rozdziela to również na control-plane (bo MCS działa na masterach).
Objaw źle ustawionego LB na 22623: instalacja niby startuje, ale węzły nie dostają konfiguracji, wiszą na ignition, bootstrap się nie kończy.
4) Wejście do aplikacji – Ingress (Router) 80/443
Trzecia “gruba” rzecz:
Ruch na:
*.apps.<cluster> → TCP/80 i TCP/443
HAProxy rozdziela ruch na węzły z ingress routerem.
W OKD router/ingress (pod router-default) zwykle działa na node’ach (często workerach, czasem infra). HAProxy robi więc rozkład ruchu na:
worker-1:80/443
worker-2:80/443
worker-3:80/443
(albo tam, gdzie masz ingress uruchomiony)
Dlaczego to ma sens?
router w OKD jest “entrypointem” do tras (Route) i dalej do serwisów w klastrze,
chcesz mieć HA dla aplikacji (jak padnie jeden worker, aplikacje dalej żyją).
5) TCP passthrough vs terminacja TLS – co HAProxy “faktycznie robi” z ruchem?
Najczęstszy i najprostszy model w OKD:
API (6443) i MCS (22623)
HAProxy robi czysty TCP load balancing (passthrough)
Nie rozpakowuje TLS, tylko przekazuje dalej
Ingress 443 (aplikacje)
Są 2 podejścia:
TCP passthrough do routerów (bardzo częste)
HAProxy tylko przekazuje TCP/443 na routery
terminacja TLS dzieje się na routerze (ingress controller)
TLS termination na HAProxy (rzadziej w OKD edge)
HAProxy kończy TLS na sobie i leci HTTP do routerów
możliwe, ale zwykle komplikujesz zarządzanie certami i SNI/Routes
W praktyce: passthrough jest prostszy i bliższy “standardowej” architekturze OKD.
6) Health-checki i “nie wysyłaj na martwego”
HAProxy zwykle robi health-checki backendów:
dla API może sprawdzać, czy port 6443 odpowiada (TCP check),
dla routerów może robić TCP check na 443/80,
czasem bardziej zaawansowane checki HTTP.
Dzięki temu:
jeśli master-2 padnie, HAProxy przestaje tam wysyłać
Instalacja i konfiguracja maszyny wirtualnej proxy
Maszyna proxy.okdlab.local będzie służyć jako proxy i load balancer dla klastra OKA oraz serwer www na czas instalacji klastra.
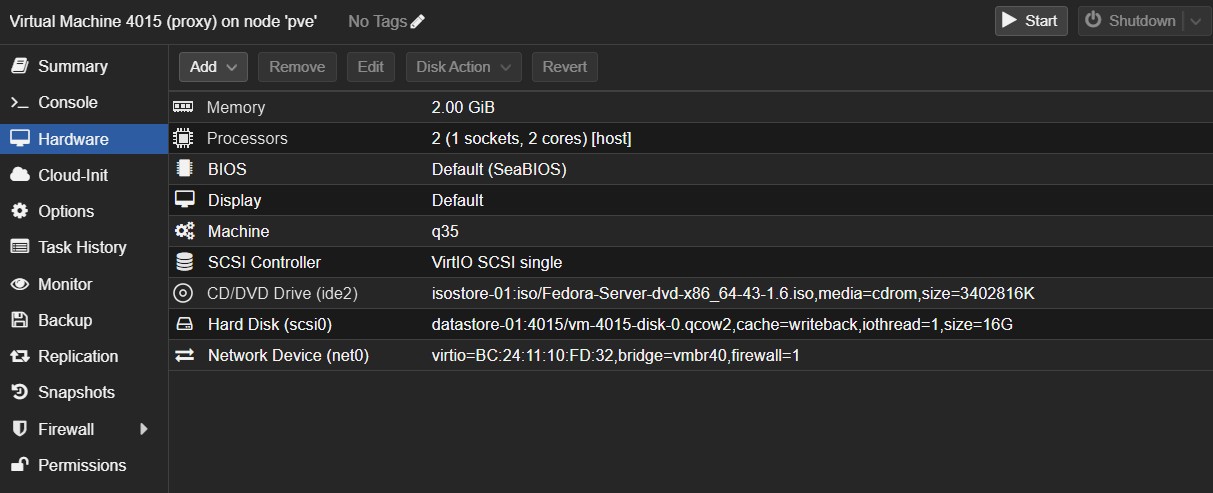
Tworzymy nową maszynę wirtualną o id 4015 i nazwie proxy z podanymi parametrami:
- Machine : q35, Qemu Agent (włączone)
- 16 GB HDD, SCSI VirtIO Single, Cache: Write Back
- 2 vCPU – 1 x Sockets, Type: Host
- 2 GB RAM , Balloning Device (włączone)
- Bridge: vmbr4, Model: VirtIO
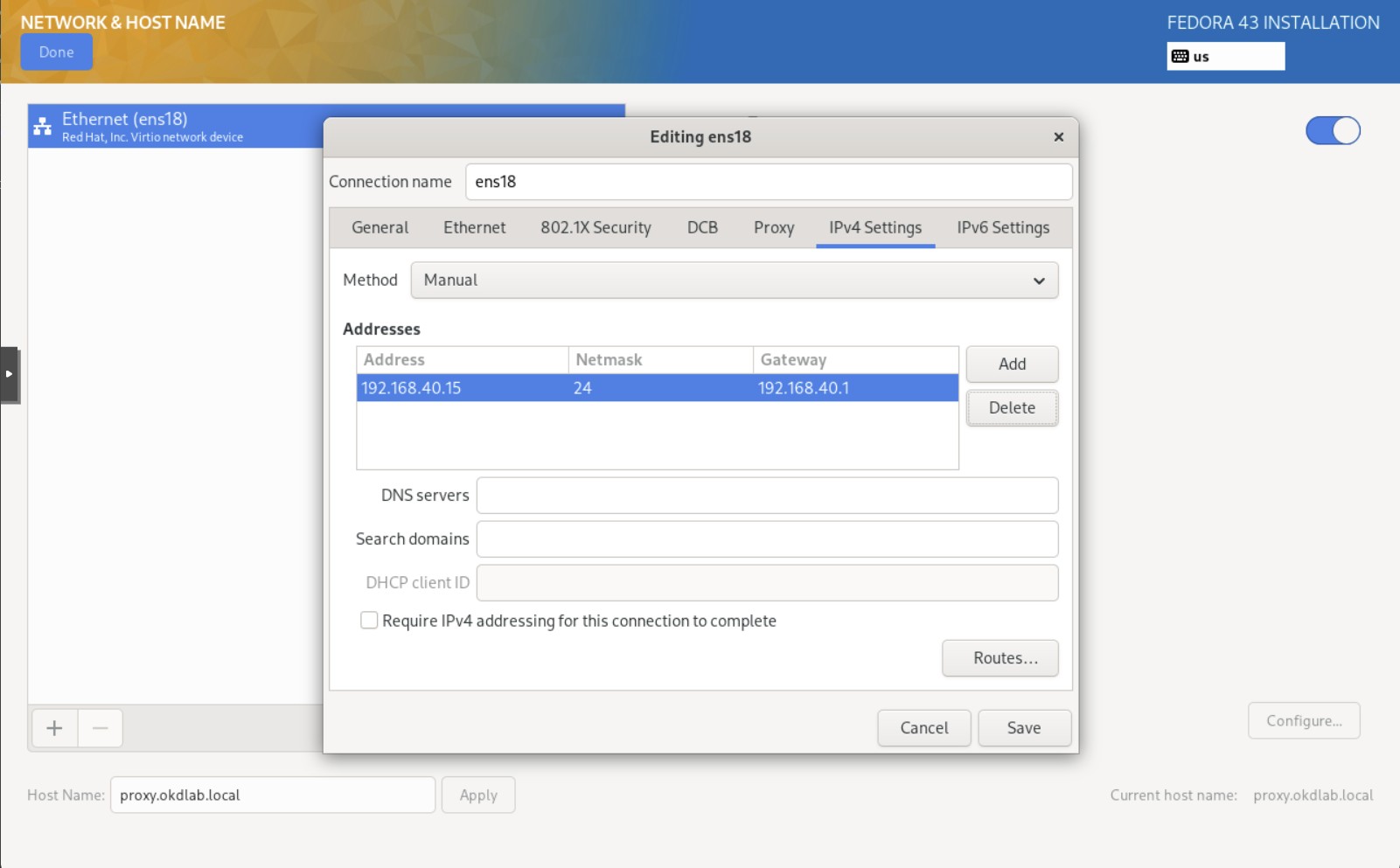
Ustawiamy prawidłową adresację sieci i nazwę hosta
- proxy.okdlab.local
- 192.168.40.15/24, brama 192.168.40.1
Włączamy konto root i ustawiamy hasło.
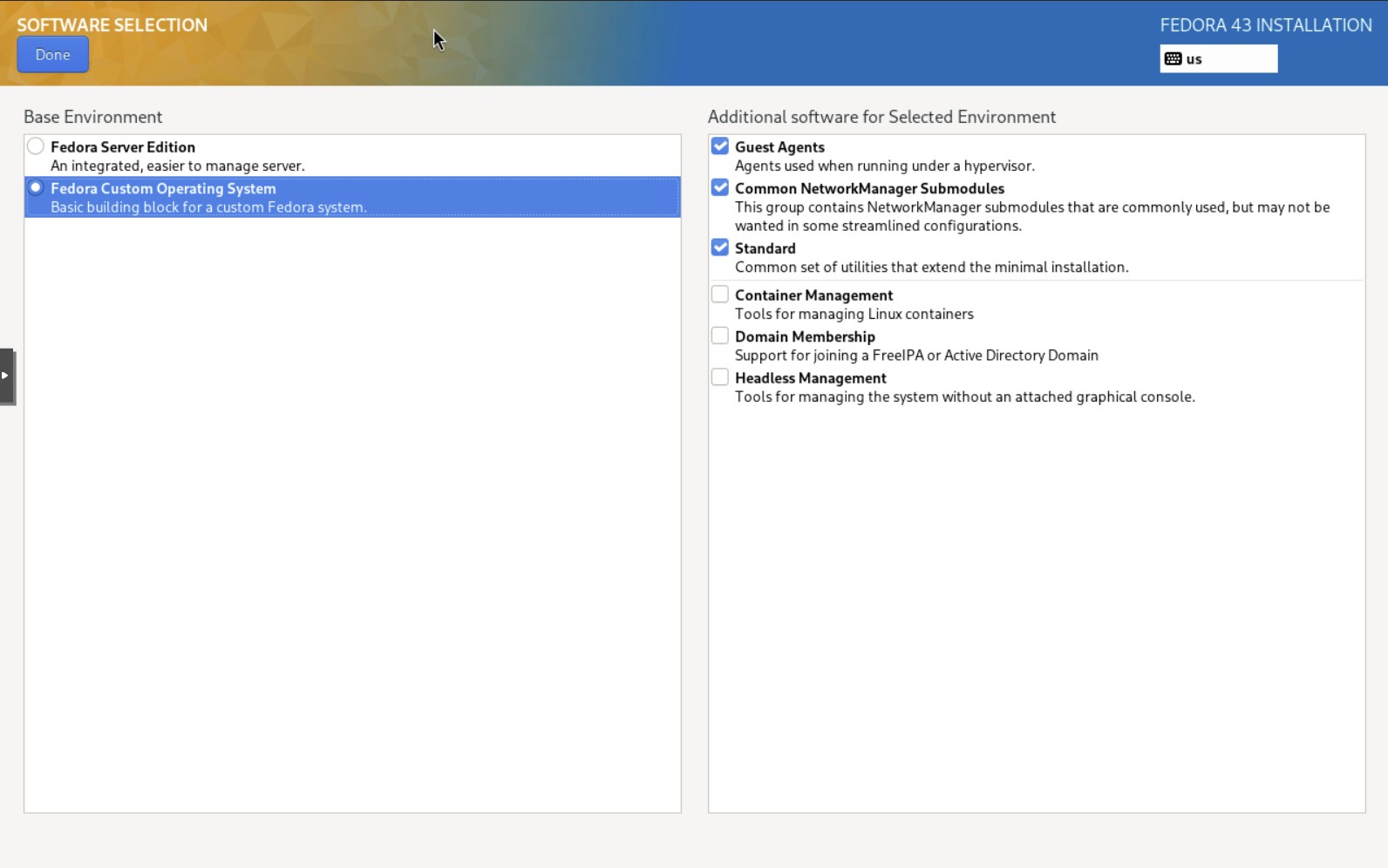
Zaznaczamy tylko wskazane opcjie w Software Selection:
- Guests Agents
- Common NetworkManager modules
- Standard
Upewniamy się co do pozostałych opcji instalacji:
- Time & Date: Europe/Warsaw
- Keyboard / Language: English (US)
- Ustawień sieci
- Wybranych pakietów do instalacji
- Konta root
Weryfikacja działania sieci i dns
Upewniamy się, że konfiguracja sieci oraz zapytania do dns działają prawidłowo.
# werryfikujemy obecne ustawienia sieci poleceniem nmcli
nmcli
ens18: connected to ens18
"Red Hat Virtio"
ethernet (virtio_net), BC:24:11:10:FD:32, hw, mtu 9000
ip4 default
inet4 192.168.40.15/24
route4 default via 192.168.40.1 metric 100
route4 192.168.40.0/24 metric 100
inet6 fe80::be24:11ff:fe10:fd32/64
route6 fe80::/64 metric 1024
lo: connected (externally) to lo
"lo"
loopback (unknown), 00:00:00:00:00:00, sw, mtu 65536
inet4 127.0.0.1/8
inet6 ::1/128
DNS configuration:
servers: 192.168.40.10 1.1.1.1
domains: okdlab.local
interface: ens18
#Sprawdź nazwę profilu połączenia
nmcli -f NAME,UUID,DEVICE,TYPE connection show --active
root@proxy:~# nmcli device show ens18 | egrep -i 'IP4.DNS|IP4.DOMAIN|IP4.GATEWAY'
# Warning: nmcli (1.54.3) and NetworkManager (1.54.0) versions don't match. Restarting NetworkManager is advised.
IP4.GATEWAY: 192.168.40.1
IP4.DNS[1]: 192.168.40.10
IP4.DNS[2]: 1.1.1.1
# gdyby powyższe nie były prawidłowe to należe to poprawić
sudo nmcli connection modify ens18 ipv4.dns-search "okdlab.local"
sudo nmcli connection modify ens18 ipv4.dns "192.168.40.10 1.1.1.1"
# po zmianach w konfiguracji sieciowej należe zrestartować interfejs
sudo nmcli connection down ens18
sudo nmcli connection up ens18
# weryfikacja działania dns
root@proxy:~# dig +short dns1.okdlab.local
192.168.40.10
root@proxy:~# dig +short proxy.okdlab.local
192.168.40.15
root@proxy:~# dig +short google.com
142.250.120.100
142.250.120.101
142.250.120.102
142.250.120.139
142.250.120.113
142.250.120.138
# sprawdzenie konfiguracji DNS
resolvectl
# sprawdzenie działania reverse dns (rekordy PTR)
dig -x 192.168.40.51
# sprawdzenie działania forward dns
nslookup compute-1.testcluster.okdlab.localUstawienia mirroru repo do aktualizacji Fedory
Jeśli router ma zablokowanie połączenia z krajami typu Rosja to może się zdarzyć błąd podczas instalacji / aktualizacji Fedora typu:
Curl error (28): Timeout was reached for http://mirror.yandex.ru/fedora/linux/updates/43/Everything/x86_64/Packages/
# aktualizacja systemu sudo nano /etc/yum.repos.d/fedora-updates.repo sudo nano /etc/yum.repos.d/fedora.repo sudo nano /etc/yum.repos.d/fedora-updates-testing.repo sudo nano /etc/yum.repos.d/fedora-cisco-openh264.repo # na koncu wszystkich metalinków dodac &country=pl na koncu metalink=https://mirrors.fedoraproject.org/metalink?repo=fedora-$releasever&arch=$basearch&country=pl sudo nano /etc/dnf/dnf.conf # Dodaj w sekcji [main] fastestmirror=True max_parallel_downloads=10 skip_if_unavailable=True # Wyczyść cache i odśwież metadane sudo dnf clean all sudo dnf makecache --refresh
Aktualizacja systemu i instalacja podstawowych narzędzi
To jest dokładnie to, czego installer i klaster oczekują w klasycznym układzie z HAProxy/LB na jednym IP.
# aktualizacja systemu sudo dnf update sudo reboot # instalacja narzędzi sudo dnf install nano mc htop curl fastfetch git screen wget ncdu nmap sysstat vnstat atop iftop -y # klient FUSE sudo dnf install sshfs -y # klient NFS sudo dnf install nfs-utils -y # klient SMB/CIFS sudo dnf install cifs-utils -y
Ustawienie swap
W Fedorze Server 43 swap nie musi być partycją ani wpisem w /etc/fstab, bo jest zwykle realizowany jako swapfile zarządzany przez systemd – konkretnie przez mechanizm zram albo systemd-swap / systemd z generatorami.
# sprawdzenie usługi tworzącaej zram sudo systemctl status [email protected] --no-pager # wyłączenie zram sudo dnf remove -y zram-generator sudo reboot # ustawienia swap w pliku sudo fallocate -l 1G /var/swap sudo chmod 600 /var/swap sudo mkswap /var/swap sudo swapon /var/swap echo '/var/swap none swap defaults 0 0' | sudo tee -a /etc/fstab
Konfiguracja fastfetch
Narzędzie fastfetch podobnie jak neofetch może pokazywać po zalogowaniu podstawowe informacje o sprzęcie i środowisku serwera.
sudo nano /root/.bashrc
# Na końcu dopisz:
# --- fastfetch banner on interactive SSH login (root) ---
if [[ $- == *i* ]] && [[ -n "$SSH_CONNECTION" || -n "$SSH_TTY" ]] && command -v fastfetch >/dev/null 2>&1; then
# nie pokazuj przy scp/rsync (często brak TTY i $- nie ma i, ale zostawmy dodatkowy bezpiecznik)
if [[ -t 1 ]]; then
fastfetch
fi
fi
Weryfikacja błędów przy starcie serwera dmesg
Jeśli znajdziemy podobne do tych błędy podczas uruchamiania systemu
sudo dmesg -T --level=err,warn
[Wed Feb 4 10:55:43 2026] shpchp 0000:05:01.0: pci_hp_register failed with error -16
[Wed Feb 4 10:55:43 2026] shpchp 0000:05:01.0: Slot initialization failed
[Wed Feb 4 10:55:43 2026] shpchp 0000:05:02.0: pci_hp_register failed with error -16
[Wed Feb 4 10:55:43 2026] shpchp 0000:05:02.0: Slot initialization failed
[Wed Feb 4 10:55:43 2026] shpchp 0000:05:03.0: pci_hp_register failed with error -16
[Wed Feb 4 10:55:43 2026] shpchp 0000:05:03.0: Slot initialization failed
[Wed Feb 4 10:55:43 2026] shpchp 0000:05:04.0: pci_hp_register failed with error -16
[Wed Feb 4 10:55:43 2026] shpchp 0000:05:04.0: Slot initialization failed
[Wed Feb 4 10:55:43 2026] device-mapper: core: CONFIG_IMA_DISABLE_HTABLE is disabled. Duplicate IMA measurements will not be recorded in the IMA log.
[Wed Feb 4 10:55:43 2026] amd_pstate: The CPPC feature is supported but currently disabled by the BIOS.
Please enable it if your BIOS has the CPPC option.
[Wed Feb 4 10:55:43 2026] amd_pstate: the _CPC object is not present in SBIOS or ACPI disabled
[Wed Feb 4 10:55:44 2026] sd 6:0:0:0: Power-on or device reset occurred
[Wed Feb 4 10:55:46 2026] snd_hda_intel 0000:00:1b.0: no codecs found!to należy wykonać następujące polecenia.
echo "blacklist snd_hda_intel" | sudo tee /etc/modprobe.d/blacklist-audio.conf echo "blacklist pciehp" | sudo tee /etc/modprobe.d/blacklist-pciehp.conf echo "blacklist shpchp" | sudo tee /etc/modprobe.d/blacklist-shpchp.conf sudo dracut -f sudo reboot sudo dnf upgrade --refresh -y sudo dnf install -y tuned sudo systemctl enable --now tuned sudo tuned-adm profile throughput-performance # sprawdź aktualne parametry dla domyślnego kernela sudo grubby --info=DEFAULT # usuń rhgb (i ewentualnie quiet) sudo grubby --update-kernel=ALL --remove-args="rhgb" # opcjonalnie: sudo grubby --update-kernel=ALL --remove-args="quiet" # reboot i sprawdź czy komunikat zniknął sudo reboot
Powinno na serwerach włączyć się pokazywanie wszystkich komunikatów błędów na konsoli podczas uruchamiania i usunąć parametr quiet z gruba.
Sprawdzenie ustawień strefy czasowej i synchronizacji czasu
Na serwerach prawie zawsze chcesz: RTC in local TZ: no (czyli RTC w UTC).
timedatectl
Local time: Wed 2026-02-04 11:14:41 CET
Universal time: Wed 2026-02-04 10:14:41 UTC
RTC time: Wed 2026-02-04 10:14:41
Time zone: Europe/Warsaw (CET, +0100)
System clock synchronized: yes
NTP service: active
RTC in local TZ: no
# gdyby strefa czasowa była niewłaściwa to należy ją zmienić np.
sudo timedatectl set-timezone Europe/Warsaw
timedatectl | grep -E 'RTC time|RTC in local TZ'
RTC time: Wed 2026-02-04 10:15:08
RTC in local TZ: no
# Logi i szybka diagnostyka “czemu nie synchronizuje”
journalctl -u systemd-timesyncd --since "1 hour ago" --no-pager
# zmiana serwera aktualizacji czasu w razie potrzeby
sudo systemctl is-active chronyd && echo "chrony aktywne"
ls -l /etc/chrony.conf /etc/chrony/chrony.conf 2>/dev/null
sudo nano /etc/chrony.conf
# zmieniamy to
...
pool 2.fedora.pool.ntp.org iburst
...
# np. na to
...
# Polska pula NTP (zalecane: 4 wpisy)
server 0.pl.pool.ntp.org iburst
server 1.pl.pool.ntp.org iburst
server 2.pl.pool.ntp.org iburst
server 3.pl.pool.ntp.org iburst
...
sudo systemctl restart chronyd
chronyc sources -v
chronyc trackingInstalacja HAProxy
sudo dnf install haproxy -y
Przygotowanie konfiguracji dla HAProxy. Poniższa konfiguracja zawiera szereg ulepszeń względem zawartości na stronie https://itadmin.vblog.ovh/klaster-okd-openshift-na-maszynach-wirtualnych-proxmox-przygotowanie-maszyny-bastion/#6-instalacja-i-konfiguracja-haproxy
- Zły adres IP dla
bootstrap - Masz
compute-3w DNS, ale HAProxy go nie używa - HAProxy i DNS są teraz “spójne”
- dla API/MCS:
balance roundrobin - dla ingress:
balance roundrobin option forwardfordziała tylko w trybie HTTP – zmieniono na TCP
global
maxconn 20000
log /dev/log local0 info
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
defaults TCP
mode tcp
log global
option tcplog
timeout connect 10s
timeout client 300s
timeout server 300s
timeout check 10s
retries 3
listen stats
bind :9000
mode http
stats enable
stats uri /
frontend okd4_k8s_api_fe
bind :6443
default_backend okd4_k8s_api_be
mode tcp
option tcplog
backend okd4_k8s_api_be
balance roundrobin
mode tcp
option tcp-check
server bootstrap 192.168.40.50:6443 check
server control-plane-1 192.168.40.51:6443 check
server control-plane-2 192.168.40.52:6443 check
server control-plane-3 192.168.40.53:6443 check
frontend okd4_machine_config_server_fe
bind :22623
default_backend okd4_machine_config_server_be
mode tcp
option tcplog
backend okd4_machine_config_server_be
balance roundrobin
mode tcp
option tcp-check
server bootstrap 192.168.40.50:22623 check
server control-plane-1 192.168.40.51:22623 check
server control-plane-2 192.168.40.52:22623 check
server control-plane-3 192.168.40.53:22623 check
frontend okd4_http_ingress_traffic_fe
bind :80
default_backend okd4_http_ingress_traffic_be
mode tcp
option tcplog
backend okd4_http_ingress_traffic_be
balance roundrobin
mode tcp
option tcp-check
server compute-1 192.168.40.61:80 check
server compute-2 192.168.40.62:80 check
server compute-3 192.168.40.63:80 check
frontend okd4_https_ingress_traffic_fe
bind *:443
default_backend okd4_https_ingress_traffic_be
mode tcp
option tcplog
backend okd4_https_ingress_traffic_be
balance roundrobin
mode tcp
option tcp-check
server compute-1 192.168.40.61:443 check
server compute-2 192.168.40.62:443 check
server compute-3 192.168.40.63:443 checkPrzed uruchomieniem HAProxy należy ustawić parametry SELinux
sudo setsebool -P haproxy_connect_any 1
lub go całkowicie wyłączyć
sudo sudo sed -i 's/^SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config sudo reboot
Włączenie usługi HAProxy
sudo systemctl enable haproxy sudo systemctl start haproxy sudo systemctl status haproxy
Zezwolenie na ruch sieciowy w firewallu
sudo firewall-cmd --permanent --add-port=6443/tcp sudo firewall-cmd --permanent --add-port=22623/tcp sudo firewall-cmd --permanent --add-service=http sudo firewall-cmd --permanent --add-service=https sudo firewall-cmd --reload
Instalacja i konfiguracja serwera httpd (Apache)
Usługa http pozwoli na wystawienie plików manifestu Kubernetes i konfiguracji ignition dla instalacji maszyn potrzebnych do zbudowania klastra OKD (OpenShift) tj. bootstrap, control-plane, compute.
sudo dnf install -y httpd sudo sed -i 's/Listen 80/Listen 8080/' /etc/httpd/conf/httpd.conf # jeśli mamy włączone SELinux sudo setsebool -P httpd_read_user_content 1 # uruchomienie usługi sudo systemctl enable httpd sudo systemctl start httpd # dodanie zezwolenie ruchu na porcie 8080 na firewallu sudo firewall-cmd --permanent --add-port=8080/tcp sudo firewall-cmd --reload # test działania serwera httpd curl localhost:8080



