

Testowy klaster OKD (OpenShift)
Poniższy wpis bazuje na konfiguracji klastra przeprowadzonej wg. wpisu https://itadmin.vblog.ovh/klaster-okd-openshift-na-maszynach-wirtualnych-proxmox-opis-instalacji/ oraz konfiguracji serwera NFS opisanej na stronie https://itadmin.vblog.ovh/klaster-okd-openshift-na-maszynach-wirtualnych-proxmox-przygotowanie-maszyny-storage-nfs/
Opis projektu OpenShift : java-cpu-burner
Projekt ma na celu kontrolowane wywołanie mechanizmu autoscalera HPA w OpenShift przez liniowe zwiększanie obciążenia CPU.
CPU będzie rosnąć liniowo → HPA spokojnie przekroczy target i zeskaluje repliki.
Plateau 90% → HPA utrzyma wyższe repliki przez kilka minut.
Spadek do 30% → HPA po chwili zmniejszy liczbę podów.
Cykl zacznie się od nowa → w konsoli OpenShift zobaczysz idealny test autoskalowania (góra–plateau–dół).
Utworzenie nowego projektu OpenShift o nazwie java-cpu-burner
Najpierw należy przygotować kod aplikacji Java , która w pętli zwiększa zużycie CPU. Pełen scenariusz testowy pod HPA:
Start na 40%
Liniowy wzrost co +5% aż do 90%
Utrzymanie 90% przez 5 minut (300 s) → HPA ma czas, żeby spokojnie zeskalować w górę
Liniowy spadek co -5% aż do 30%
cięższe obliczenia (Math.sin, Math.tan w pętli) zamiast lekkiego Math.sqrt
większa intensywność (load * 100_000 zamiast load * 10_000) → CPU faktycznie się „męczy”
więcej wątków (cores * 2 zamiast cores) → szybciej widać obciążenie na całym node
cykl: wzrost → plateau (5 min) → spadek → od nowa
Cykl powtarza się w nieskończoność
public class CpuBurnerCycle {
public static void main(String[] args) {
printBanner();
int sleepBeforeStart = getEnvAsInt("SLEEP_BEFORE_START", 5);
int loopDelaySec = getEnvAsInt("LOOP_DELAY", 10); // co ile sekund zmieniamy load
int minLoad = getEnvAsInt("MIN_LOAD", 40); // startowe obciążenie (%)
int maxLoad = getEnvAsInt("MAX_LOAD", 90); // końcowe obciążenie (%)
int step = getEnvAsInt("STEP", 10); // krok zmiany (%)
int plateauSec = getEnvAsInt("PLATEAU_SEC", 300); // plateau na max load (domyślnie 5 minut)
System.out.println("Konfiguracja CPU Burner (cykl):");
System.out.println(" - SLEEP_BEFORE_START = " + sleepBeforeStart + "s");
System.out.println(" - LOOP_DELAY = " + loopDelaySec + "s");
System.out.println(" - MIN_LOAD = " + minLoad + "%");
System.out.println(" - MAX_LOAD = " + maxLoad + "%");
System.out.println(" - STEP = " + step + "%");
System.out.println(" - PLATEAU_SEC = " + plateauSec + "s");
try {
Thread.sleep(sleepBeforeStart * 1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
int cores = Runtime.getRuntime().availableProcessors();
int workers = cores * 2; // zwiększamy równoległość
System.out.println("Wykryto CPU cores = " + cores + ", uruchamiam workerów = " + workers);
for (int i = 0; i < workers; i++) {
Thread worker = new Thread(() -> {
try {
int iteration = 0;
while (true) {
// 1️⃣ Wzrost od MIN_LOAD do MAX_LOAD
for (int load = minLoad; load <= maxLoad; load += step) {
iteration++;
runLoadPhase(iteration, load, loopDelaySec);
}
// 2️⃣ Plateau na MAX_LOAD
int plateauIterations = plateauSec / loopDelaySec;
for (int j = 0; j < plateauIterations; j++) {
iteration++;
runLoadPhase(iteration, maxLoad, loopDelaySec);
}
// 3️⃣ Spadek od MAX_LOAD do MIN_LOAD
for (int load = maxLoad; load >= minLoad; load -= step) {
iteration++;
runLoadPhase(iteration, load, loopDelaySec);
}
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
worker.start();
}
System.out.println("CPU Burner działa w trybie cyklicznym: wzrost → plateau → spadek → od nowa.");
}
private static void runLoadPhase(int iteration, int load, int loopDelaySec) throws InterruptedException {
System.out.println("Iteracja #" + iteration +
" → docelowe obciążenie CPU ≈ " + load + "%");
long endTime = System.currentTimeMillis() + (loopDelaySec * 1000L);
// utrzymujemy obciążenie na tym poziomie przez loopDelaySec
while (System.currentTimeMillis() < endTime) {
long start = System.nanoTime();
// aktywna część = cięższe spalanie CPU
while ((System.nanoTime() - start) < (load * 100_000)) {
double dummy = 0;
for (int i = 0; i < 1000; i++) {
dummy += Math.sin(i) * Math.tan(i);
}
if (dummy == 42.0) { // zabezpieczenie przed optymalizacją JIT
System.out.print("");
}
}
// pasywna część = odpoczynek CPU
Thread.sleep((100 - load) * 10L);
}
}
private static int getEnvAsInt(String name, int defaultValue) {
String value = System.getenv(name);
if (value != null) {
try {
return Integer.parseInt(value);
} catch (NumberFormatException e) {
System.err.println("Niepoprawna wartość dla " + name + ": " + value +
" (używam domyślnej " + defaultValue + ")");
}
}
return defaultValue;
}
private static void printBanner() {
System.out.println("===================================");
System.out.println(" J C B");
System.out.println(" JAVA CPU BURNER");
System.out.println(" wersja 1.0.1.A");
System.out.println("===================================");
}
}Następnie należy przygotować odpowiedni Dockerfile, który posłuży do zbudowania obrazu aplikacji. Będą w nim parametry środowiskowe, które łatwo można nadpisać configmapą z OpenShifta.
W tym projekcie jednak nie będziemy tworzyć i podłączać configmapy tylko skupimy się na HPA.
FROM eclipse-temurin:17-jdk-alpine
# ustawiamy strefę czasową
RUN apk add --no-cache tzdata \
&& cp /usr/share/zoneinfo/Europe/Warsaw /etc/localtime \
&& echo "Europe/Warsaw" > /etc/timezone
WORKDIR /app
# kopiujemy kod źródłowy
COPY CpuBurnerCycle.java /app
# kompilujemy
RUN javac CpuBurnerCycle.java
# zmienne środowiskowe (do sterowania z ConfigMapy / oc set env)
ENV SLEEP_BEFORE_START=5
ENV LOOP_DELAY=10
ENV MIN_LOAD=30
ENV MAX_LOAD=90
ENV PLATEAU_SEC=300
# uruchamiamy aplikację
CMD ["java", "CpuBurnerCycle"]Teraz możemy przystąpić do utworzenia projektu o nazwie java-cpu-burner oraz build configa i image stream-a o wskazanej dowolnej nazwie np. java-cpu-burner-build
oc new-project java-cpu-burner # stworzenie build nowego obrazu bazującego na Dockerfile oc new-build --strategy=docker --binary --name=java-cpu-burner-build
Następny krokiem jest zbudowanie obrazu czyli builda o nazwie java-cpu-burner-build
cd /home/bastuser/repo/java-cpu-burner oc start-build java-cpu-burner-build --from-dir=. --follow
Weryfikujemy czy powyższy build wykonał się poprawnie.
# sprawdzenie dostępnych buildów w projekcie
oc get builds
NAME TYPE FROM STATUS STARTED DURATION
java-cpu-burner-build-1 Docker Binary Complete 26 seconds ago 20s
# przejrzenie logów z builda
oc logs -f build/java-cpu-burner-build-1
# ostatnie zdarzenia w projekcie gdzie widać szczegóły powstawania builda w projekcie
oc get events --sort-by='{.lastTimestamp}' -n java-cpu-burnerUtworzenie aplikacji OpenShift
Teraz możemy utworzyć aplikację na bazie istniejącego builda jako deployment-config do którego możemy dodać pvc oraz configmap.
# aplikacja czyli pody mają się zaczynąc od java-memoryeater-app oc new-app java-cpu-burner-build:latest --name=java-cpu-burner-app --as-deployment-config
Monitorowanie logów POD-a
Z poziomu konsoli tekstowej oc logs -f <nazwa poda>
oc logs -f java-cpu-burner-app-1-xlrtb Konfiguracja CPU Burner (cykl): - SLEEP_BEFORE_START = 5s - LOOP_DELAY = 10s - MIN_LOAD = 30% - MAX_LOAD = 90% - PLATEAU_SEC = 300s Wykryto CPU cores = 4 CPU Burner działa w trybie cyklicznym: rośnie, plateau, spada, od nowa. Iteracja #1 → docelowe obciążenie CPU ≈ 30% Iteracja #1 → docelowe obciążenie CPU ≈ 30% Iteracja #1 → docelowe obciążenie CPU ≈ 30% Iteracja #1 → docelowe obciążenie CPU ≈ 30% Iteracja #2 → docelowe obciążenie CPU ≈ 35% Iteracja #2 → docelowe obciążenie CPU ≈ 35% Iteracja #2 → docelowe obciążenie CPU ≈ 35% Iteracja #2 → docelowe obciążenie CPU ≈ 35% Iteracja #3 → docelowe obciążenie CPU ≈ 40% Iteracja #3 → docelowe obciążenie CPU ≈ 40% ... Iteracja #14 → docelowe obciążenie CPU ≈ 90%
Z poziomu konsoli graficznej jako Developer – projekt – pod – zakładka Logs
Monitorowanie wykorzystanie CPU przez POD-a
Z poziomu konsoli tekstowej
# sprawdzamy które pody wykorzystują najwięcej zasobów na klastrze oc adm top pods -n java-cpu-burner NAME CPU(cores) MEMORY(bytes) java-cpu-burner-app-1-xlrtb 37m 20Mi # sprawdzamy na którego workera na klastrze trafił pod oc get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES java-cpu-burner-app-1-deploy 0/1 Completed 0 5m7s 10.129.2.47 compute-3 <none> <none> java-cpu-burner-app-1-xlrtb 1/1 Running 0 5m6s 10.129.2.48 compute-3 <none> <none> java-cpu-burner-build-1-build 0/1 Completed 0 7m6s 10.129.2.46 compute-3 <none> <none> # sprawdzamy zuzyćie zasobów na workerze w klastrze oc adm top nodes NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% compute-1 244m 6% 3687Mi 24% compute-2 252m 7% 3442Mi 23% compute-3 80m 2% 1733Mi 11% control-plane-1 393m 11% 5611Mi 37% control-plane-2 348m 9% 4271Mi 28% control-plane-3 311m 8% 4160Mi 27%
Z poziomu konsoli graficznej jako Developer – projekt – pod
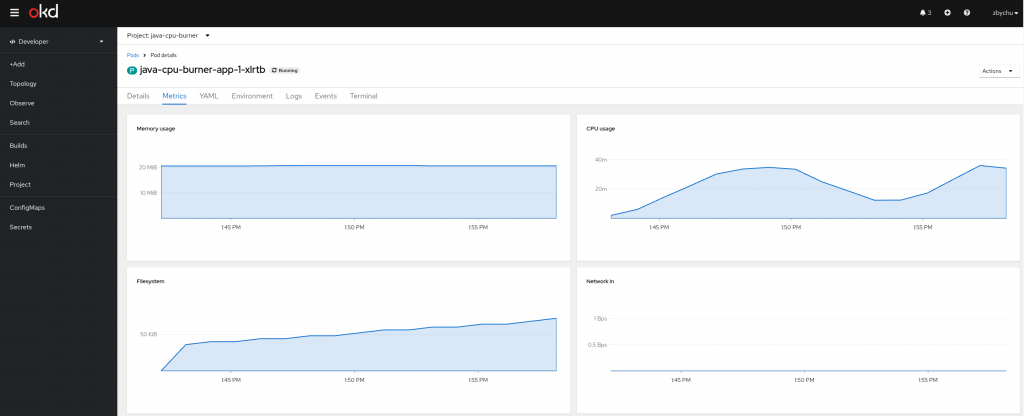
Ustawianie HPA w projekcie
Celem tego zadania jest ustawienie limitów dla CPU oraz parametrów wyzwalania skalowania horyzontalnego HPA.
Najpierw należy ustawić odpowiednie limity na zasoby np. tak jak poniżej.
# ustawiamy parametry, że pod nie moze zużyc więcej niż 500m CPU
oc set resources dc/java-cpu-burner-app --limits=cpu=500m,memory=512Mi --requests=cpu=100m,memory=256Mi -n java-cpu-burner
# wymuszenie nowych wartość w podzie po restarcie
oc rollout latest dc/java-cpu-burner-app -n java-cpu-burner
# weryfikujemy na podzie jakie limity go obowiązują
oc describe pod java-cpu-burner-app-12-x4qjd | grep -A5 "Limits"
Limits:
cpu: 500m
memory: 512Mi
Requests:
cpu: 100m
memory: 256MiRola limits
limits=500m → kontener nie może przekroczyć pół vCPU. Dzięki temu nie „pożre” całego noda.
Ale HPA nie patrzy na limits, tylko na requests.
Jak działa HPA
HorizontalPodAutoscaler (HPA) liczy obciążenie CPU w procentach względem requests.cpu.
Formuła:
CPU% = (aktualne użycie CPU) / (requests.cpu) * 100
limits → określa sufit (ile maksymalnie kontener może zużyć).
requests → to gwarantowane minimum i punkt odniesienia dla HPA.
czyli jeśli pod pokazuje np. 499m to formuła wygląda tak: 499m/ 100m = 499%
oc adm top pods NAME CPU(cores) MEMORY(bytes) java-cpu-burner-app-12-46wcq 499m 17Mi
Dodajemy HPA do projektu
# podajemy minimalną i maksymalną liczbę replik podów oraz próg uruchomienia repliki (70%) oc autoscale dc/java-cpu-burner-app --min=1 --max=5 --cpu-percent=70 -n java-cpu-burner
# po dobrych kilku minutach gdy sprawdzamy stan HPA powinno pojawić się wykorzystanie ponad 500 % CPU i będzie do 5 stopniowa zwiększać się ilośc replik oc get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE java-cpu-burner-app DeploymentConfig/java-cpu-burner-app 499%/70% 1 5 4 56m
Sprawdzenie jakie limity RAM / CPU obowiązują danego POD-a. Sprawdzamy sekcję Limits i Requests.
oc describe hpa java-cpu-burner-app -n java-cpu-burner Name: java-cpu-burner-app Namespace: java-cpu-burner Labels: <none> Annotations: <none> CreationTimestamp: Fri, 03 Oct 2025 14:30:36 +0200 Reference: DeploymentConfig/java-cpu-burner-app Metrics: ( current / target ) resource cpu on pods (as a percentage of request): 501% (501m) / 70% Min replicas: 1 Max replicas: 5 DeploymentConfig pods: 5 current / 5 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ReadyForNewScale recommended size matches current size ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request) ScalingLimited True TooManyReplicas the desired replica count is more than the maximum replica count
HPA widzi już 500% 🚀
→ czyli działa dokładnie tak, jak zakładaliśmy (usage=499m / requests=100m ≈ 500%).
Target = 70%
→ czyli HPA wie, że trzeba dodać więcej podów.
DeploymentConfig pods: 1 current / 5 desired
→ HPA faktycznie policzył, że powinno być 5 podów, i ustawił taki stan w spec.
Widać na poniższym ekranie 5 uruchomionych podów
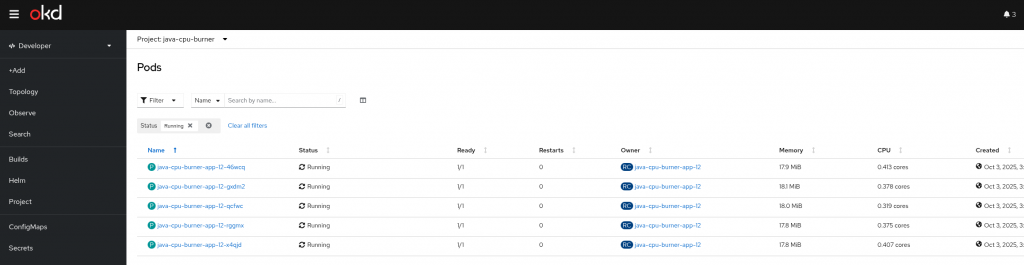
Powrót do mniejszej ilości replik
Dlaczego HPA wolno skaluje w dół?
To celowe – żeby uniknąć „flappingu” (ciągłego góra/dół, jeśli obciążenie chwilowo spada).
W Kubernetes/Openshift HPA domyślnie czeka 5 minut (300 sekund) zanim zmniejszy liczbę replik.
Można to ustawienie nadpisać przy poniższym HPA z stabilizationWindowSeconds: 30 zejście z 5→1 pod(a) nastąpi zwykle w ~30–60 s po spadku poniżej targetu.
# hpa-fast-dc.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: java-cpu-burner-app
namespace: java-cpu-burner
spec:
scaleTargetRef:
apiVersion: apps.openshift.io/v1
kind: DeploymentConfig
name: java-cpu-burner-app
minReplicas: 1
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
behavior:
# Agresywny SCALE-UP: natychmiast (bez stabilizacji), duże skoki
scaleUp:
stabilizationWindowSeconds: 0
selectPolicy: Max
policies:
- type: Pods
value: 4 # może dodać do 4 podów na jedno „okno”
periodSeconds: 15
- type: Percent
value: 100 # lub podwoić liczbę replik w 15 s
periodSeconds: 15
# Szybki SCALE-DOWN: krótka stabilizacja i duże redukcje
scaleDown:
stabilizationWindowSeconds: 30 # zamiast domyślnych ~300 s
selectPolicy: Max
policies:
- type: Pods
value: 4 # może zdjąć do 4 podów w 30 s
periodSeconds: 30
- type: Percent
value: 100 # lub zredukować nawet o 100% (do minReplicas)
periodSeconds: 30
Nadpisanie domyślnych ustawień HPA w projekcie
# Zachowuje Twoją obecną architekturę (DC). Szybko skaluje w górę i w dół. oc apply -f hpa-fast-dc.yaml Warning: resource horizontalpodautoscalers/java-cpu-burner-app is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by oc apply. oc apply should only be used on resources created declaratively by either oc create --save-config or oc apply. The missing annotation will be patched automatically. horizontalpodautoscaler.autoscaling/java-cpu-burner-app configured
Teraz można szybko przetestować skalowanie w górę i w dół. Poniżej opisano jak zmniejszyć wykorzystanie CPU w pod-ach aby obserwować szybkie skalowanie w dół.
# zmnniejszamy radykalnie poziom wykorzystania CPU do 10 %
oc set env dc/java-cpu-burner-app MIN_LOAD=5 MAX_LOAD=10 -n java-cpu-burner
oc rollout latest dc/java-cpu-burner-app -n java-cpu-burner
# zużycie CPU powinno wyraznie spaść
oc adm top pods
NAME CPU(cores) MEMORY(bytes)
java-cpu-burner-app-15-4x67c 43m 17Mi
java-cpu-burner-app-15-772wl 44m 17Mi
java-cpu-burner-app-15-nw8cs 43m 17Mi
java-cpu-burner-app-15-smdfg 45m 17Mi
java-cpu-burner-app-15-thdr8 43m 17Mi
# w logacg poda widac zablokowane do 10% obciazenie
oc logs -f java-cpu-burner-app-15-4x67c
===================================
J C B
JAVA CPU BURNER
wersja 1.0.1.B
===================================
Konfiguracja CPU Burner (cykl):
- SLEEP_BEFORE_START = 5s
- LOOP_DELAY = 10s
- MIN_LOAD = 5%
- MAX_LOAD = 10%
- STEP = 10%
- PLATEAU_SEC = 300s
Wykryto CPU cores = 1, uruchamiam workerów = 4
Iteracja #1 → docelowe obciążenie CPU ≈ 5%
CPU Burner działa w trybie cyklicznym: wzrost → plateau → spadek → od nowa.
Iteracja #1 → docelowe obciążenie CPU ≈ 5%
Iteracja #1 → docelowe obciążenie CPU ≈ 5%
Iteracja #1 → docelowe obciążenie CPU ≈ 5%
Iteracja #2 → docelowe obciążenie CPU ≈ 10%
Iteracja #2 → docelowe obciążenie CPU ≈ 10%
Iteracja #2 → docelowe obciążenie CPU ≈ 10%
Iteracja #2 → docelowe obciążenie CPU ≈ 10%
...
# po kilku minutach widać że w kolumnie target zmniejsza się powoli wykorzystanie CPU i ilośc replik podów
watch -n 5 'oc get hpa,dc,rc,pods -n java-cpu-burner'
Warning: apps.openshift.io/v1 DeploymentConfig is deprecated in v4.14+, unavailable in v4.10000+
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/java-cpu-burner-app DeploymentConfig/java-cpu-burner-app 44%/70% 1 5 2 126m
NAME REVISION DESIRED CURRENT TRIGGERED BY
deploymentconfig.apps.openshift.io/java-cpu-burner-app 15 2 2 config,image(java-cpu-burner-build:latest)
NAME DESIRED CURRENT READY AGE
replicationcontroller/java-cpu-burner-app-10 0 0 0 82m
replicationcontroller/java-cpu-burner-app-11 0 0 0 80m
replicationcontroller/java-cpu-burner-app-12 0 0 0 75m
replicationcontroller/java-cpu-burner-app-13 0 0 0 39m
replicationcontroller/java-cpu-burner-app-14 0 0 0 38m
replicationcontroller/java-cpu-burner-app-15 2 2 2 27m
replicationcontroller/java-cpu-burner-app-5 0 0 0 127m
replicationcontroller/java-cpu-burner-app-6 0 0 0 126m
replicationcontroller/java-cpu-burner-app-7 0 0 0 126m
replicationcontroller/java-cpu-burner-app-8 0 0 0 87m
replicationcontroller/java-cpu-burner-app-9 0 0 0 82m
NAME READY STATUS RESTARTS AGE
pod/java-cpu-burner-app-10-deploy 0/1 Completed 0 82m
pod/java-cpu-burner-app-11-deploy 0/1 Completed 0 80m
pod/java-cpu-burner-app-12-deploy 0/1 Completed 0 75m
pod/java-cpu-burner-app-13-deploy 0/1 Completed 0 39m
pod/java-cpu-burner-app-14-deploy 0/1 Completed 0 38m
pod/java-cpu-burner-app-15-deploy 0/1 Completed 0 27m
pod/java-cpu-burner-app-15-nw8cs 1/1 Running 0 27m
pod/java-cpu-burner-app-15-smdfg 1/1 Running 0 27m
pod/java-cpu-burner-app-5-deploy 0/1 Completed 0 127m
pod/java-cpu-burner-app-6-deploy 0/1 Completed 0 126m
pod/java-cpu-burner-app-7-deploy 0/1 Completed 0 126m
pod/java-cpu-burner-app-8-deploy 0/1 Completed 0 87m
pod/java-cpu-burner-app-9-deploy 0/1 Completed 0 82m
pod/java-cpu-burner-build-1-build 0/1 Completed 0 177m
pod/java-cpu-burner-build-2-build 0/1 Completed 0 127m
pod/java-cpu-burner-build-3-build 0/1 Completed 0 87m
pod/java-cpu-burner-build-4-build 0/1 Completed 0 80m
# ręczne wyskalowanie do 1 pod-a gdy nie mamy cierpliwości aby poczekać
oc scale dc/java-cpu-burner-app --replicas=1 -n java-cpu-burnerSam proces skalowania można też podglądać w eventach projektu.
oc get events --sort-by='{.lastTimestamp}' -n java-cpu-burner
15m Warning FailedGetResourceMetric horizontalpodautoscaler/java-cpu-burner-app failed to get cpu utilization: did not receive metrics for targeted pods (pods might be unready)
11m Normal Killing pod/java-cpu-burner-app-15-4x67c Stopping container java-cpu-burner-build
11m Normal SuccessfulDelete replicationcontroller/java-cpu-burner-app-15 Deleted pod: java-cpu-burner-app-15-4x67c
11m Normal ReplicationControllerScaled deploymentconfig/java-cpu-burner-app Scaled replication controller "java-cpu-burner-app-15" from 5 to 4
6m20s Normal Killing pod/java-cpu-burner-app-15-772wl Stopping container java-cpu-burner-build
6m20s Normal SuccessfulRescale horizontalpodautoscaler/java-cpu-burner-app New size: 3; reason: All metrics below target
6m20s Normal ReplicationControllerScaled deploymentconfig/java-cpu-burner-app Scaled replication controller "java-cpu-burner-app-15" from 4 to 3
6m20s Normal SuccessfulDelete replicationcontroller/java-cpu-burner-app-15 Deleted pod: java-cpu-burner-app-15-772wl
2m49s Normal Killing pod/java-cpu-burner-app-15-thdr8 Stopping container java-cpu-burner-build
2m49s Normal ReplicationControllerScaled deploymentconfig/java-cpu-burner-app Scaled replication controller "java-cpu-burner-app-15" from 3 to 2
2m49s Normal SuccessfulDelete replicationcontroller/java-cpu-burner-app-15 Deleted pod: java-cpu-burner-app-15-thdr8
2m49s Normal SuccessfulRescale horizontalpodautoscaler/java-cpu-burner-app New size: 2; reason: All metrics below target

