

Opis Ollama
Projekt ma na celu kontrolowane wywołanie częstego błędu w aplikacjach java: OutOfMemoryError poprzez cykliczne pożeranie pamięci RAM. Bazuje na oOllama to lokalny serwer modeli językowych (LLM), który pozwala uruchamiać i używać dużych modeli AI — takich jak LLaMA, Mistral, DeepSeek czy Phi — bezpośrednio na własnym komputerze lub serwerze, bez połączenia z chmurą.
Działa podobnie do Dockera: możesz „pobrać” (ollama pull) model z biblioteki, uruchomić go (ollama run lub przez API) i komunikować się z nim w trybie czatu lub programowo. Ollama ma wbudowany lekki REST API (port 11434), który pozwala integrować modele z aplikacjami, np. Open WebUI, terminalem lub własnym skryptem. Obsługuje GPU (CUDA, ROCm, Metal) oraz różne poziomy kwantyzacji modeli (np. Q4_K_M, Q8_0), dzięki czemu można dobrać modele pod dostępny VRAM. W skrócie — to open-source’owy backend AI, który zamienia Twój komputer w prywatny lokalny ChatGPT
Utworzenie nowej maszyny wirtualnej Proxmox 9: ubuntu-ai
Jeśli mamy już skonfigurowane passthrough GPU na hoście Proxmox 9 to możemy przystąpić do konfiguracji i instalacji maszyny wirtualnej bazującej na Ubuntu Server 24.04.3 LTS https://ubuntu.com/download/server
wg. poniższego wzorca. Ilość vCPU i RAM należy dobrać do swoich możliwości i potrzeb. Nie ma tutaj ograniczeń ponieważ bazujemy głównie na karcie graficznej RTX 5070 Ti 16 GB VRAM.
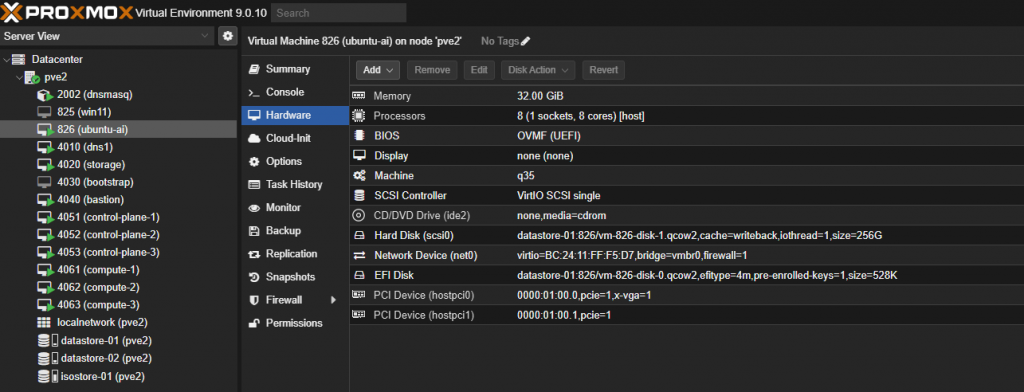
Dodanie karty graficznej czyli PCI Dervice oraz zmianę Display na none najwygodniej jest przeprowadzić po zakończonej instalacji i udostępnieniu połączenia do maszyny przez SSH.
# sprawdzamy czy maszyna wirtualna widzi kartę graficzną lspci | grep VGA 01:00.0 VGA compatible controller: NVIDIA Corporation Device 2c05 (rev a1) # aktualizacja i instalacja sterowników sudo apt update && sudo apt upgrade -y sudo apt install ubuntu-drivers-common -y sudo ubuntu-drivers autoinstall sudo reboot # instalacja narzędzia nvtop sudo apt install nvtop -y
Weryfikacja poprawności działania karty graficznej RTX 5070 Ti
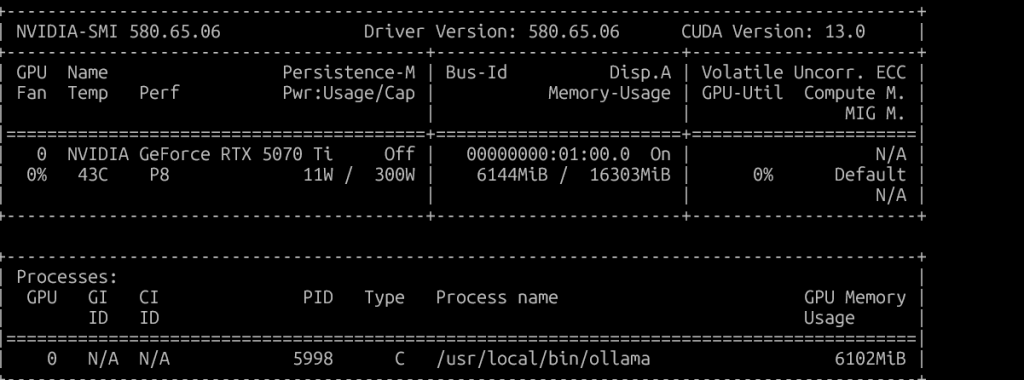
Sprawdzamy poleceniem nvidia-smi czy wszystko jest w porządku
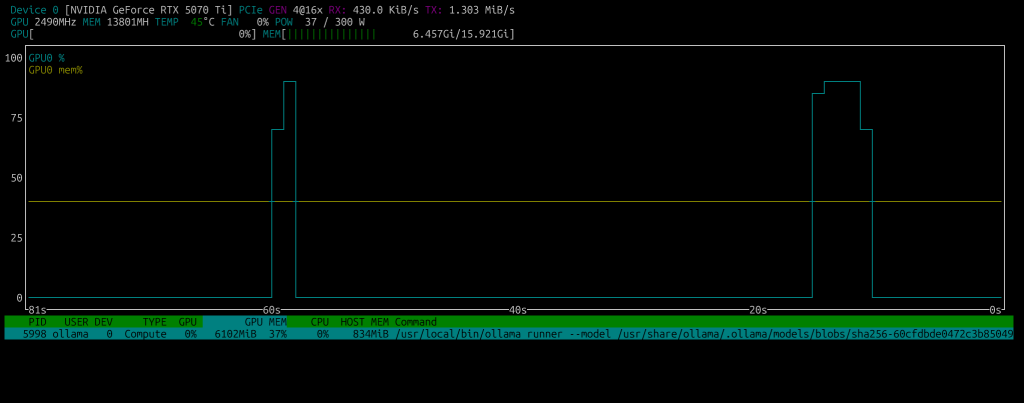
Obciążenie GPU i VRAM możemy podglądać na bieżąco używając narzędzia vtop
Instalacja Ollama
Ollama to demon działający jako backend LLM — wspiera GPU NVIDIA out-of-the-box.
# automatyczna instalacja Ollama curl -fsSL https://ollama.com/install.sh | sh >>> Installing ollama to /usr/local >>> Downloading Linux amd64 bundle ######################################################################## 100.0% >>> Creating ollama user... >>> Adding ollama user to render group... >>> Adding ollama user to video group... >>> Adding current user to ollama group... >>> Creating ollama systemd service... >>> Enabling and starting ollama service... Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service. >>> NVIDIA GPU installed. # weryfikacja działania usługi ollama sudo systemctl status ollama
Uruchomienie modelu DeepSeek
Najlżejsze warianty, które mieszczą się w 16 GB VRAM:
| Model | VRAM wymagane (FP16) | VRAM z quant. Q4_K_M | Opis |
|---|---|---|---|
| deepseek-coder:1.3b | ~4 GB | ~2 GB | bardzo szybki, mały model do kodu |
| deepseek-coder:6.7b | ~13 GB | ~8 GB | idealny dla 16 GB VRAM |
| deepseek-llm:7b | ~14 GB | ~8–9 GB | uniwersalny językowy |
| deepseek-math:7b | ~15 GB | ~9 GB | wyspecjalizowany w matematyce i logice |
Jak zmieścić model w 16 GB VRAM ?
Kluczowa zasada: używaj kwantyzacji (quantization)
Modele w formacie .gguf w Ollama są często dostępne w kilku wariantach:
| Nazwa wariantu | Typ kwantyzacji | RAM/VRAM użycie | Jakość |
|---|---|---|---|
Q8_0 | 8-bit | bardzo wysoka, duży VRAM | 15–16 GB |
Q6_K | 6-bit | bardzo dobra | 12–13 GB |
Q4_K_M | 4-bit | dobra, szybka | 7–8 GB |
Q3_K_L | 3-bit | średnia, bardzo lekka | 5–6 GB |
# pobranie uniwersalnego modelu językowego ollama pull deepseek-llm:7b # i jego uruchomienie ollama run deepseek-llm:7b
Po pobraniu i uruchomieniu wskazanego modelu, możemy rozmawiać z modelem.
Instalacja Open WebUI
Open WebUI to idealny frontend dla Ollama (i innych backendów LLM, np. LM Studio czy LocalAI).
Aby nie kolidował z innymi aplikacjami najlepiej zainstalować Open WebUI jako kontener Docker-a.
# jeśli nie mam python 3 (w ubuntu 24 już jest) sudo apt install python3 python3-venv python3-pip -y sudo apt update sudo apt install docker.io docker-compose -y sudo systemctl enable docker sudo systemctl start docker
Uruchamiamy kontener open-webui
mkdir -p ~/open-webui cd ~/open-webui docker run -d --name open-webui --network host -v ~/open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --restart always ghcr.io/open-webui/open-webui:main # weryfikujemy działanie docker logs -f open-webui
Weryfikacja działania połączenia Ollama z Open WebUI
Z innego komputera w przeglądarce wchodzimy na adres naszej maszyny ubuntu-ai np. : http://192.168.8.26:8080/
Korzystanie z API Ollamy
Możemy z dowolnego innego komputera czy serwera odpytywać Ollamę zdalnie używając np. curl-a
curl -s http://192.168.8.26:11434/api/tags | jq '.'
{
"models": [
{
"name": "deepseek-llm:7b",
"model": "deepseek-llm:7b",
"modified_at": "2025-09-30T21:51:36.167847223Z",
"size": 4000473688,
"digest": "9aab369a853bb12b8187d14eca701385f0a564cd2ae938fb4cbdb31bf2d43fc2",
"details": {
"parent_model": "",
"format": "gguf",
"family": "llama",
"families": null,
"parameter_size": "7B",
"quantization_level": "Q4_0"
}
}
]
}
# wersja serwera
curl -s http://192.168.8.26:11434/api/version
# aktywne sesje modeli
curl -s http://192.168.8.26:11434/api/ps | jq
# szczegóły wybranego modelu
curl -s http://192.168.8.26:11434/api/show -d '{
"model": "deepseek-llm:7b"
}' | jq
# pobranie nowego modlu
curl -s http://192.168.8.26:11434/api/pull -d '{
"name": "llama3:8b"
}'
# dodanie własnego modelu
curl -X POST http://192.168.8.26:11434/api/create -d '{
"model": "moja-baza:1",
"modelfile": "FROM llama3:8b\nSYSTEM You are a cybersecurity expert assistant."
}'
# usuniecie modelu
curl -s http://192.168.8.26:11434/api/delete -d '{
"model": "phi3-mini:3.8b"
}'Możemy tworzyć dowolne zapytania przy użyciu API i formatować jej odpowiedź do bardziej czytelnej formy:
curl -s http://192.168.8.26:11434/api/generate -d '{
"model": "deepseek-llm:7b",
"prompt": "Wytłumacz, czym jest GPU passthrough w Proxmox 9 w 3 zdaniach."
}' | jq -r -c '.response?' | tr -d '\n'; echoOdpowiedź Ollamy
GPU passthrough to technika używana w systemie Proxmox Kubernetes Engine (KGE) do przekierowywania wykonawczych procesorów graficznych GPU i ich pamięć do serwerem zdalnego, który może je potrzebować. W 3 zdaniach można powiedzieć, że GPU passthrough to technika umożliwiająca urządzeniom zdalnym, takim jak maszyny wirtualne lub serwerowe systemy kontrolowane przez Proxmox, używanie wykonawczych procesorów graficznych GPU.
Problem ze zdalnym dostępem do API Ollama
Jeśli Ollama nasłuchuje tylko na lokalnym interfejsie i jest dostępna przez 127.0.0.1 to należy zmienić ten adres na 0.0.0.0.
sudo mkdir -p /etc/systemd/system/ollama.service.d/
printf '[Service]\nEnvironment="OLLAMA_HOST=0.0.0.0"\n' | sudo tee /etc/systemd/system/ollama.service.d/override.conf
sudo systemctl restart ollama
# weryfikacja
ss -tulpn | grep 11434
tcp LISTEN 0 4096 *:11434 *:* users:(("ollama",pid=4861,fd=3))Problem z odnalezieniem GPU przez usługę Ollama po restarcie maszyny wirtualnej
Jeśli w logach usługi Ollama jest informacja typu o compatible GPUs were discovered
systemctl status ollama
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; preset: enabled)
Drop-In: /etc/systemd/system/ollama.service.d
└─override.conf
Active: active (running) since Tue 2025-10-07 06:46:05 UTC; 18s ago
Main PID: 930 (ollama)
Tasks: 10 (limit: 38395)
Memory: 43.5M (peak: 43.8M)
CPU: 90ms
CGroup: /system.slice/ollama.service
└─930 /usr/local/bin/ollama serve
Oct 07 06:46:06 ubuntu-ai ollama[930]: time=2025-10-07T06:46:05.978Z level=INFO source=routes.go:1475 msg="server config" env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GF>
Oct 07 06:46:06 ubuntu-ai ollama[930]: time=2025-10-07T06:46:05.980Z level=INFO source=images.go:518 msg="total blobs: 4"
Oct 07 06:46:06 ubuntu-ai ollama[930]: time=2025-10-07T06:46:05.981Z level=INFO source=images.go:525 msg="total unused blobs removed: 0"
Oct 07 06:46:06 ubuntu-ai ollama[930]: time=2025-10-07T06:46:05.981Z level=INFO source=routes.go:1528 msg="Listening on [::]:11434 (version 0.12.3)"
Oct 07 06:46:06 ubuntu-ai ollama[930]: time=2025-10-07T06:46:05.982Z level=INFO source=gpu.go:217 msg="looking for compatible GPUs"
Oct 07 06:46:06 ubuntu-ai ollama[930]: time=2025-10-07T06:46:06.004Z level=INFO source=gpu.go:621 msg="no nvidia devices detected by library /usr/lib/x86_64-linux-gnu/libcuda.so.580.65.06"
Oct 07 06:46:06 ubuntu-ai ollama[930]: time=2025-10-07T06:46:06.014Z level=INFO source=gpu.go:396 msg="no compatible GPUs were discovered"
Oct 07 06:46:06 ubuntu-ai ollama[930]: time=2025-10-07T06:46:06.014Z level=INFO source=types.go:131 msg="inference compute" id=0 library=cpu variant="" compute="" driver=0.0 name="" total="31.3 GiB" available=>
Oct 07 06:46:05 ubuntu-ai systemd[1]: Started ollama.service - Ollama Service.
Oct 07 06:46:19 ubuntu-ai ollama[930]: [GIN] 2025/10/07 - 06:46:19 | 200 | 729.3µs | 127.0.0.1 | GET "/api/version"A polecenie nvidia-smi pokazuje prawidłowe informacje diagnostyczne o karcie graficznej to oznacza to, że usługa ollama startuje zbyt wcześnie i należy ją dostosować.
sudo systemctl edit ollama ### Editing /etc/systemd/system/ollama.service.d/override.conf ### Anything between here and the comment below will become the contents of the drop-in file [Service] Environment="OLLAMA_HOST=0.0.0.0" [Unit] After=multi-user.target systemd-modules-load.service nvidia-persistenced.service [Service] ExecStartPre=/bin/sleep 10 ### Edits below this comment will be discarded ### /etc/systemd/system/ollama.service # [Unit] # Description=Ollama Service # After=network-online.target # # [Service] # ExecStart=/usr/local/bin/ollama serve # User=ollama # Group=ollama # Restart=always # RestartSec=3 # Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin" # # [Install] # WantedBy=default.target





