

Opis Ollama
Ollama to lokalny serwer modeli językowych (LLM), który pozwala uruchamiać i używać dużych modeli AI — takich jak LLaMA, Mistral, DeepSeek czy Phi — bezpośrednio na własnym komputerze lub serwerze, bez połączenia z chmurą. Obsługuje GPU (CUDA, ROCm, Metal) oraz różne poziomy kwantyzacji modeli (np. Q4_K_M, Q8_0), dzięki czemu można dobrać modele pod dostępny VRAM. W skrócie — to open-source’owy backend AI, który zamienia Twój komputer w prywatny lokalny ChatGPT
Przygotowanie Proxmox 9 pod passthrough GPU dla vm win11-ai
Jeśli mamy już skonfigurowane passthrough GPU na hoście Proxmox 9 to możemy przystąpić do konfiguracji i instalacji maszyny wirtualnej wg. poniższego wzorca.
Ilość vCPU i RAM należy dobrać do swoich możliwości i potrzeb. Nie ma tutaj ograniczeń ponieważ bazujemy głównie na karcie graficznej RTX 5070 Ti 16 GB VRAM.
w biosie igfx na primatry 64 MB
echo "root=$(grep -o 'root=[^ ]*' /proc/cmdline) amd_iommu=on iommu=pt" > /etc/kernel/cmdline
proxmox-boot-tool refresh
1.3 Doładuj moduły VFIO i zablokuj sterowniki NVIDIA na hoście
Ryzen 9 7900 ma iGPU, więc wygodnie jest nie ładować sterowników NVIDIA na hoście — karta zostanie czysta dla VFIO.
# /etc/modules-load.d/vfio.conf
printf "vfio\nvfio_iommu_type1\nvfio_pci\nvfio_virqfd\n" > /etc/modules-load.d/vfio.conf
# zablokuj sterowniki nvidia i nouveau na HOŚCIE:
cat >/etc/modprobe.d/blacklist-nvidia.conf <<'EOF'
blacklist nouveau
blacklist nvidia
blacklist nvidia_drm
blacklist nvidia_modeset
options nouveau modeset=0
EOF
update-initramfs -u
reboot
root@pve2:~# lspci -nn | grep -i nvidia
01:00.0 VGA compatible controller [0300]: NVIDIA Corporation GB203 [GeForce RTX 5070 Ti] [10de:2c05] (rev a1)
01:00.1 Audio device [0403]: NVIDIA Corporation Device [10de:22e9] (rev a1)
lspci -k -s 01:00.0
01:00.0 VGA compatible controller: NVIDIA Corporation GB203 [GeForce RTX 5070 Ti] (rev a1)
Subsystem: ASUSTeK Computer Inc. Device 89f6
Kernel modules: nvidiafb, nouveau
host trzyma kartę powinno być Kernel modules: vfio-pci → karta już jest „czysta” i gotowa do passthrough (idealnie).
echo "options vfio-pci ids=10de:2c05,10de:22e9 disable_vga=1" > /etc/modprobe.d/vfio-pci-ids.conf
update-initramfs -u
reboot
teraz pokazuje OK
root@pve2:~# lspci -k -s 01:00.0
01:00.0 VGA compatible controller: NVIDIA Corporation GB203 [GeForce RTX 5070 Ti] (rev a1)
Subsystem: ASUSTeK Computer Inc. Device 89f6
Kernel driver in use: vfio-pci
Kernel modules: nvidiafb, nouveauUtworzenie nowej maszyny wirtualnej Proxmox 9: win11-ai
Jeśli mamy już skonfigurowane passthrough GPU na hoście Proxmox 9 to możemy przystąpić do konfiguracji i instalacji maszyny wirtualnej wg. poniższego wzorca.
Ilość vCPU i RAM należy dobrać do swoich możliwości i potrzeb. Nie ma tutaj ograniczeń ponieważ bazujemy głównie na karcie graficznej RTX 5070 Ti 16 GB VRAM.
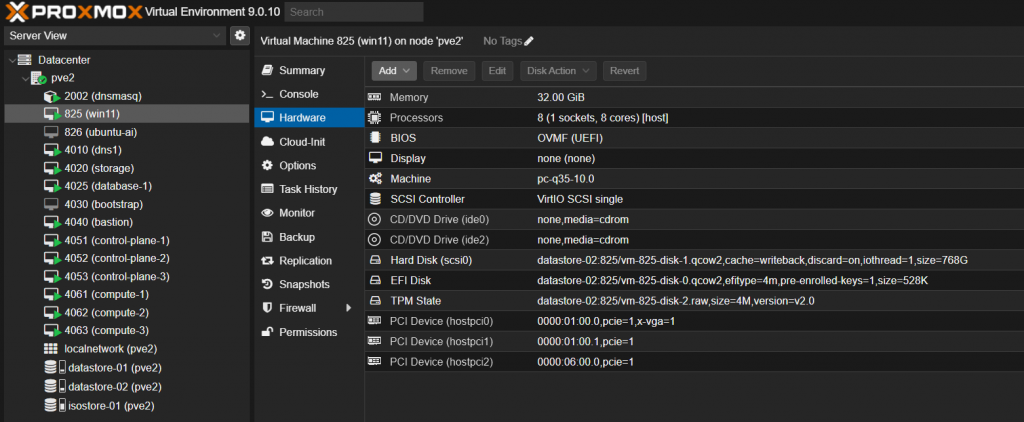
Dodanie karty graficznej czyli PCI Dervice oraz zmianę Display na none najwygodniej jest przeprowadzić po zakończonej instalacji i udostępnieniu połączenia do maszyny przez RDP.
# sprawdzamy czy maszyna wirtualna widzi kartę graficzną agent: 1 bios: ovmf boot: order=scsi0;ide2;ide0 cores: 8 cpu: host efidisk0: datastore-02:825/vm-825-disk-0.qcow2,efitype=4m,pre-enrolled-keys=1,size=528K hostpci0: 0000:01:00.0,pcie=1,x-vga=1 hostpci1: 0000:01:00.1,pcie=1 hostpci2: 0000:06:00.0,pcie=1 ide0: none,media=cdrom ide2: none,media=cdrom machine: pc-q35-10.0 memory: 32768 meta: creation-qemu=10.0.2,ctime=1755371831 name: win11 numa: 0 ostype: win11 scsi0: datastore-02:825/vm-825-disk-1.qcow2,cache=writeback,discard=on,iothread=1,size=768G scsihw: virtio-scsi-single smbios1: uuid=f8de995c-18f8-413a-88d8-ee128f678a74 sockets: 1 startup: order=11,up=30,down=15 tablet: 0 tpmstate0: datastore-02:825/vm-825-disk-2.raw,size=4M,version=v2.0 vga: none vmgenid: 282a3120-3350-4791-84c0-8a29047efa34
Weryfikacja poprawności działania karty graficznej RTX 5070 Ti
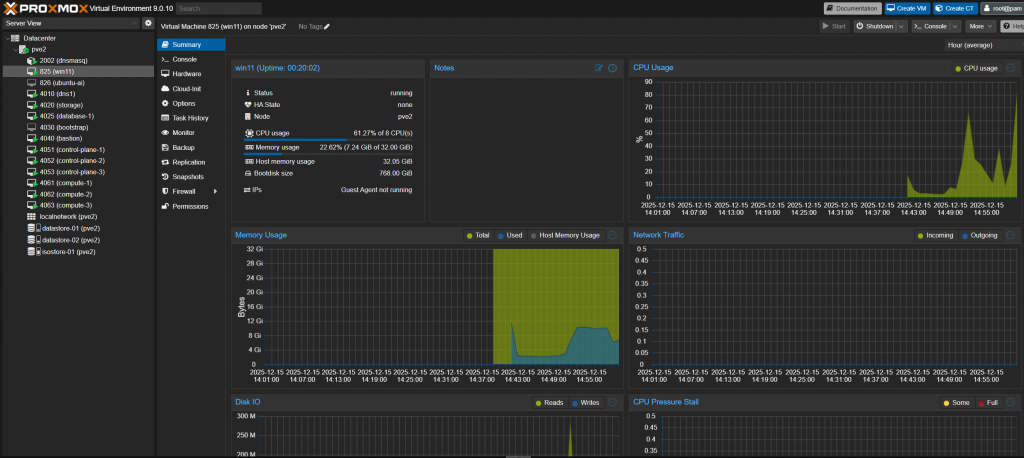
Sprawdzamy poleceniem nvidia-smi czy wszystko jest w porządku
Obciążenie GPU i VRAM możemy podglądać na bieżąco używając narzędzia vtop
Instalacja Ollama
Ollama to demon działający jako backend LLM — wspiera GPU NVIDIA out-of-the-box.
Rekomendowany porządek (najmniej problemów) Instalacja Win11 na „zwykłej” konsoli PVE Display: STD VGA / SPICE (czyli nie „None”). Dysk: SCSI + VirtIO, sterowniki z ISO VirtIO podczas instalacji. (Opcjonalnie) tymczasowa VirtIO NIC, żeby pobrać aktualizacje/sterowniki szybciej. Wyłącz VM. Dodaj GPU i NIC w passthrough Hardware → Add → PCI Device → wybierz GPU (…:00.0 + zaznacz All functions dla …:00.1 Audio) → PCI-Express ✔. Nie ustawiaj jeszcze „Primary GPU” i nie zmieniaj Display na „None” — zostaw wirtualny ekran jako „awaryjny” podgląd przez noVNC. Dodaj NIC (passthrough), PCI-Express ✔. Uruchom VM z wirtualnym ekranem + GPU Windows wykryje nowe urządzenia. Zainstaluj sterowniki GPU (NVIDIA/AMD) i sterowniki NIC (jeśli wymagane). Sprawdź w Menedżerze urządzeń: brak żółtych wykrzykników, GPU działa, sieć działa. Przełączenie na „prawdziwy” obraz z GPU (opcjonalnie) Wyłącz VM. W PCI Device (GPU) zaznacz Primary GPU. Ustaw Display = None (eliminuje konflikt z wirtualną grafiką). Uruchom VM — obraz i dźwięk pójdą przez kartę (masz wpięty fake HDMI, więc monitor „istnieje”). Gdy potwierdzisz, że sieć w VM działa po passtrough NIC, możesz usunąć tymczasową VirtIO NIC.
Uruchomienie modelu DeepSeek
Najlżejsze warianty, które mieszczą się w 16 GB VRAM:
| Model | VRAM wymagane (FP16) | VRAM z quant. Q4_K_M | Opis |
|---|---|---|---|
| deepseek-coder:1.3b | ~4 GB | ~2 GB | bardzo szybki, mały model do kodu |
| deepseek-coder:6.7b | ~13 GB | ~8 GB | idealny dla 16 GB VRAM |
| deepseek-llm:7b | ~14 GB | ~8–9 GB | uniwersalny językowy |
| deepseek-math:7b | ~15 GB | ~9 GB | wyspecjalizowany w matematyce i logice |
Jak zmieścić model w 16 GB VRAM ?
Kluczowa zasada: używaj kwantyzacji (quantization)
Modele w formacie .gguf w Ollama są często dostępne w kilku wariantach:
| Nazwa wariantu | Typ kwantyzacji | RAM/VRAM użycie | Jakość |
|---|---|---|---|
Q8_0 | 8-bit | bardzo wysoka, duży VRAM | 15–16 GB |
Q6_K | 6-bit | bardzo dobra | 12–13 GB |
Q4_K_M | 4-bit | dobra, szybka | 7–8 GB |
Q3_K_L | 3-bit | średnia, bardzo lekka | 5–6 GB |
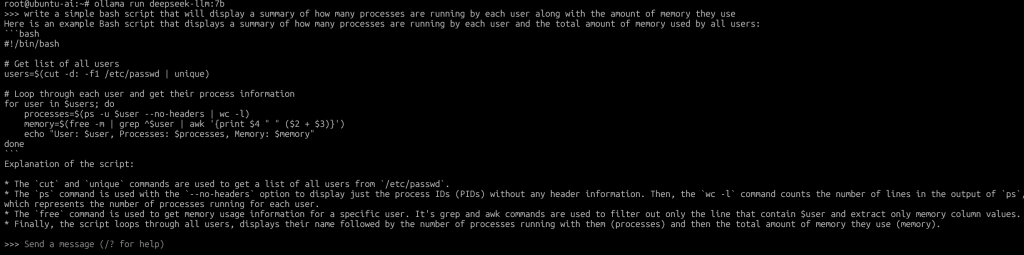
# pobranie uniwersalnego modelu językowego ollama pull deepseek-llm:7b # i jego uruchomienie ollama run deepseek-llm:7b
Po pobraniu i uruchomieniu wskazanego modelu, możemy rozmawiać z modelem.
Instalacja Stabilty Matrix
Open WebUI to idealny frontend dla Ollama (i innych backendów LLM, np. LM Studio czy LocalAI).
Aby nie kolidował z innymi aplikacjami najlepiej zainstalować Open WebUI jako kontener Docker-a.
# jeśli nie mam python 3 (w ubuntu 24 już jest) sudo apt install python3 python3-venv python3-pip -y sudo apt update sudo apt install docker.io docker-compose -y sudo systemctl enable docker sudo systemctl start docker
U




