

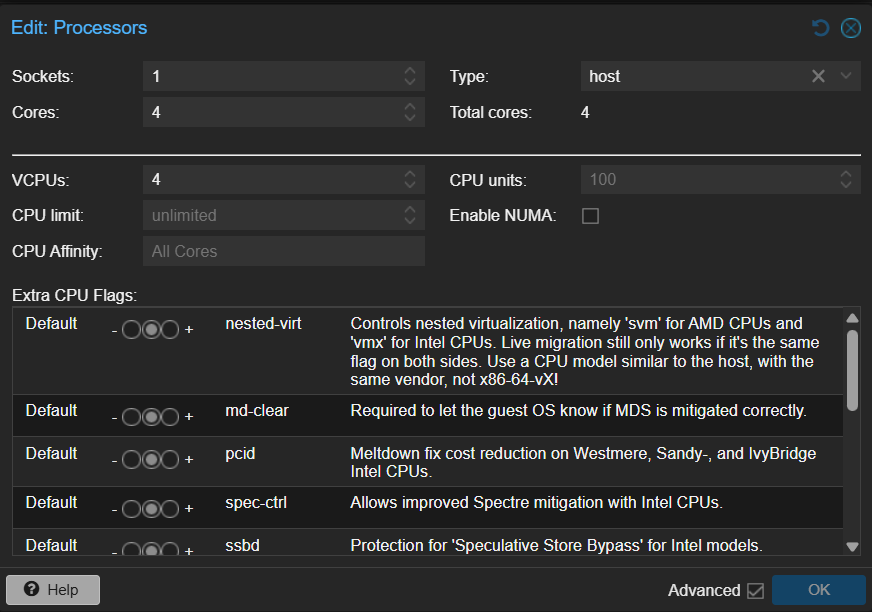
Ustawienia w zakładce Processors maszyny wirtualnej
- NUMA: na moim Ryzenie nie ma obsługi. Najczęściej nie ma sensu włączać dla małych/średnich VM. Zostaw OFF.
- Topologia: wybieraj 1 socket. Czyli 1 socket / 4 cores zamiast 2 socket / 2 cores.
- Type: host
Jak sprawdzić, czy host w ogóle ma NUMA > 1 node?
lscpu | egrep -i 'NUMA|Socket|Thread|Core|CPU\(s\)' numactl -H 2>/dev/null || echo "Brak numactl albo 1 node NUMA"
Po co w ogóle ktoś robi 2 socket w VM?
- licencjonowanie (Windows Server / stare zasady per-socket),
- jakieś bardzo specyficzne zachowania schedulerów/softu,
- testowanie topologii.
W normalnym życiu (Linux VM, usługi, k8s, docker, gitlab, jenkins):
2 socket po 2 cores nie daje przewagi nad 1 socket 4 cores, a czasem bywa gorsze (scheduler, wykrywanie topologii, software myśli że to “wielo-CPU” zamiast “wielo-rdzeniowe”).
cpu: host oznacza:
- VM dostaje dokładny model CPU hosta
- przekazywane są realne instrukcje (SSE4, AVX, AVX2, AES, itp.)
- brak sztucznego ograniczania feature setu
NUMA: na Twoim Ryzenie najczęściej nie ma sensu włączać dla małych/średnich VM. Zostaw OFF.
Topologia: wybieraj 1 socket. Czyli 1 socket / 4 cores zamiast 2 socket / 2 cores.
Określanie liczby potrzebnych vCPU dla maszyny wirtualnej
Zweryfikuj Load i steal time w środku VM
uptime top vmstat 1
Obciążenie CPU w Proxmox (per VM). Jeśli VM regularnie dobija do wysokiego CPU (np. >70% przy 2 vCPU) → warto dodać.
pvesh get /cluster/resources --type vm | egrep 'qemu/|cpu' │ id │ type │ cgroup-mode │ content │ cpu │ disk │ diskread │ diskwrite │ hastate │ level │ lock │ maxcpu │ maxdisk │ maxmem │ mem │ memhost │ name │ netin │ netout │ network │ network-type │ node │ plugintype │ pool │ protocol │ sdn │ status │ storage │ tags │ template │ uptime │ vmid │ zone-type │ │ qemu/1021 │ qemu │ │ │ 0.00% │ 0.00 B │ 0.00 B │ 0.00 B │ │ │ │ 4 │ 16.00 GiB │ 2.00 GiB │ 0.00 B │ 0.00 B │ pbs │ 0.00 B │ 0.00 B │ │ │ pve │ │ │ │ │ stopped │ │ debian_11 │ 0 │ 0s │ 1021 │ │ │ qemu/1022 │ qemu │ │ │ 0.38% │ 0.00 B │ 220.37 MiB │ 15.86 MiB │ │ │ │ 2 │ 16.00 GiB │ 1.00 GiB │ 308.52 MiB │ 344.51 MiB │ remote │ 77.42 KiB │ 3.90 KiB │ │ │ pve │ │ │ │ │ running │ │ ubuntu_22.04 │ 0 │ 40m 31s │ 1022 │ │ │ qemu/1025 │ qemu │ │ │ 3.79% │ 0.00 B │ 1.81 GiB │ 461.10 MiB │ │ │ │ 2 │ 64.00 GiB │ 16.00 GiB │ 5.54 GiB │ 5.28 GiB │ docker │ 481.10 MiB │ 537.85 MiB │
Ustawienia swap
Kompresony swap 8GB w pamięci ma priorytet 100 a z pliku 8 GB /var/swapfile ma priorytet 10.
apt update && apt install -y zram-tools systemctl restart zramswap swapon --show
# Compression algorithm selection # speed: lz4 > zstd # compression: zstd > lz4 # This is not inclusive of all that is available in latest kernels # See /sys/block/zram0/comp_algorithm (when zram module is loaded) to see # what is currently set and available for your kernel[1] # [1] https://www.kernel.org/doc/html/latest/admin-guide/blockdev/zram.html#select-compression-algorithm ALGO=zstd # Specifies the amount of RAM that should be used for zram # based on a percentage the total amount of available memory # This takes precedence and overrides SIZE below #PERCENT=50 # Specifies a static amount of RAM that should be used for # the ZRAM devices, this is in MiB SIZE=8192 # Specifies the priority for the swap devices, see swapon(2) # for more details. Higher number = higher priority # This should probably be higher than hdd/ssd swaps. PRIORITY=100
fallocate -l 8G /var/swapfile chmod 600 /var/swapfile mkswap /var/swapfile swapon /var/swapfile swapon -p 10 /var/swapfile grep -q '^/var/swapfile ' /etc/fstab || echo '/var/swapfile none swap sw,pri=10 0 0' >> /etc/fstab
Weryfikacj czy oba swapy są włączone
root@pve:/etc/pve/nodes/pve/qemu-server# swapon --output-all NAME TYPE SIZE USED PRIO UUID LABEL /dev/zram0 partition 8G 36K 100 4afdb274-28b1-465b-b40c-61ae2ae8a2cd /var/swapfile file 8G 0B 10 34508111-6d5e-40f5-93d0-8609b6e1b7b7
Jak szybko ocenić, czy dobrałeś dobrze?
free -h vmstat 1 sar -W 1 10 # jeśli masz sysstat Linux 6.17.4-2-pve (pve) 02/23/2026 _x86_64_ (24 CPU) 01:49:35 PM pswpin/s pswpout/s 01:49:36 PM 0.00 0.00 01:49:37 PM 0.00 0.00 ... # Statystyki zram cat /sys/block/zram0/mm_stat 40960 1986 94208 0 94208 0 0 0 0
Jeśli widzisz:
- stale rosnący si/so w vmstat (swap in/out),
- i spadek responsywności,
to swap jest używany „na poważnie” i trzeba raczej: - zmniejszyć presję RAM (limity, ARC, ballooning),
- albo dołożyć RAM,
- a nie tylko powiększać swap.
Przydział pamięci maszynom wirtualnym
- obniż “MAX memory” tam gdzie jest ewidentny zapas
- włącz ballooning (dynamiczny RAM) dla VM (QEMU)
memory = MAX, ile VM może dostać w piku (Twoja górka)
balloon = MIN, ile VM ma mieć gwarantowane nawet gdy host jest pod presją (Twoja “podłoga”)
# Aktualne zużycie RAM per VM/CT (żeby zobaczyć kto naprawdę je) pvesh get /cluster/resources --type vm --output-format=json-pretty # Dla CT: pvesh get /nodes/$(hostname)/lxc --output-format=json-pretty
Poniższe polecenie wypisze zawartość wszystkich configów VM (qemu) i CT (lxc) z czytelnymi nagłówkami:
for d in /etc/pve/nodes/$(hostname)/qemu-server /etc/pve/nodes/$(hostname)/lxc; do \
echo -e "\n===== $(basename "$d") ====="; \
for f in "$d"/*.conf; do \
[ -e "$f" ] || continue; \
echo -e "\n### $(basename "$f") ###"; \
sed 's/\r$//' "$f"; \
done; \
doneDla oszczędności pamięci RAM należy szczególnie w maszynach vm z systemem Linux usatwiań balloning, inaczej Proxmox/QEMU rezerwuje hostowi RAM “na sztywno” do wysokości przydziału, nawet jeśli w środku gość realnie używa mniej. Przykład:
# dla vm qm set 1021 --memory 8192 --balloon 4096 # dla kontenera pct set 2030 -memory 4096 -swap 1024
Małe 1–2 GB VM (dns, nut, proxy, icinga, pbs, webserver)
MAX: zostaw jak jest
MIN: 50–75% MAX
1 GB → MIN 512–768
2 GB → MIN 1024–1536
Średnie 4 GB VM (bastion, database-1, n8n, haos)
MIN zwykle 2048–3072
jeśli ważna stabilność: 3072
jeśli ma być “bardziej elastycznie”: 2048
Duże 8–16 GB VM (gitlab, docker, jenkins, k8s)
MIN raczej 60–90%
docker/jenkins: MIN 4096–8192 (zależnie od roli)
gitlab (8GB): MIN 6144
k8s: MIN wysoko (często 70–90%)



